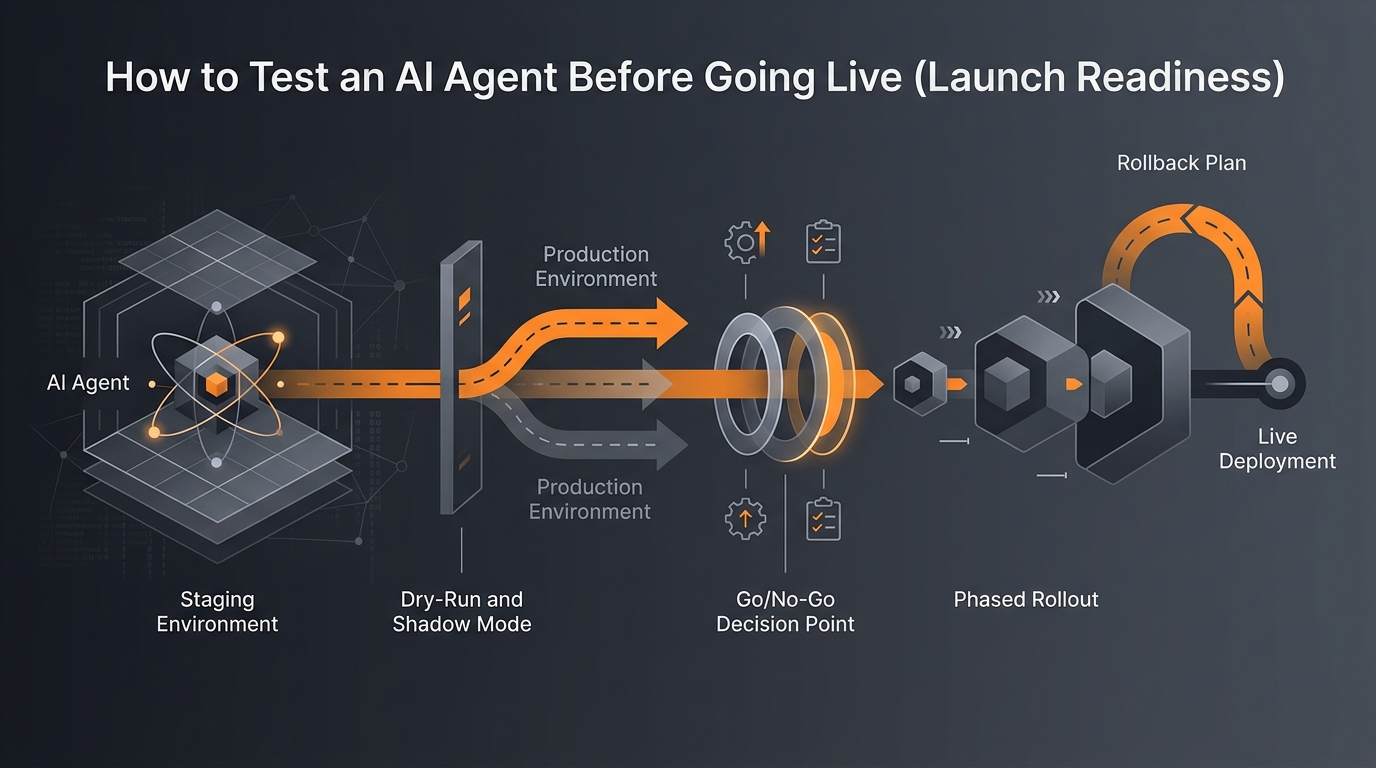
An agent that passes every test in the lab can still fail on its first real day. Test data is tidy; the real world is not. Going live is its own discipline, separate from proving the agent works on known cases, and skipping it is how teams end up with an agent that quietly sends the wrong email to a thousand customers. Launch readiness is the set of steps that take an agent from "works on my test set" to "safe to point at production".
This guide covers the go-live process: staging, dry runs and shadow mode, the go or no-go decision, a phased rollout, and a rollback plan. It assumes you have already done the correctness work in how to test an AI agent before you deploy it; this post is about the launch itself, not the test design. Think of that piece as proving the agent is right, and this one as proving it is ready.
Readiness, not just testing
It helps to separate two questions that often get blurred. "Does the agent do the right thing?" is a correctness question, answered by running it against known inputs and checking the outputs. "Is the agent ready to touch real systems and real users?" is a readiness question, and a perfect score on the first does not answer the second. An agent can be entirely correct on test cases and still be unready because nothing has confirmed how it behaves against live data, live load, and live consequences.
Launch readiness exists because the gap between test and reality is where agents surprise you. Real inputs are messier, real systems fail in ways your mocks did not, and a mistake against production has consequences a test never does. The steps below close that gap deliberately, so the first real run is boring rather than dramatic. The underlying reliability mindset is the subject of AI agent reliability testing explained.
Start in staging
The first move toward live is a staging environment: a copy of production that the agent can act in without real consequences. Staging uses test accounts, sandbox API keys, and throwaway data, so the agent can send, write, and delete freely while nothing real is touched. It is the place to confirm that the agent's integrations actually work end to end, not just that the logic is sound.
What staging catches
Staging surfaces the unglamorous failures that unit tests miss: an API that behaves differently from its mock, a permission the agent lacks, a rate limit, a malformed payload that only the real service rejects. These are integration problems, and they are common precisely because they live in the seams between systems. An agent that runs clean against real services in staging has cleared a bar that no amount of isolated testing can prove, which is why staging comes before any live exposure and why it pairs with watching the agent's behaviour through how to monitor agent activity.
Dry run and shadow mode
The most revealing pre-launch step is shadow mode. Here the agent runs on real, live inputs, but its actions are blocked: instead of sending the email, it records the email it would have sent. You then compare what it proposed against what should have happened. Shadow mode gives you the one thing staging cannot, the genuine distribution of real-world inputs, while keeping the safety of a dry run where no action lands.
Reading shadow results
The value of shadow mode is in the disagreements. Where the agent's proposed action matches the right answer, you gain confidence; where it diverges, you have found a real failure that test data never would have shown. Run it long enough to see the messy edge cases that only real traffic produces, an oddly formatted record, an unusual request, a state you did not anticipate. A few days of clean shadow results is far stronger evidence of readiness than any synthetic test suite, and the failures it surfaces map onto the known AI agent failure modes.
Go or no-go criteria
Before launch, write down the specific conditions the agent must meet to go live, and agree them in advance so the decision is not made on launch-day optimism. Good criteria are measurable: a minimum accuracy on the test set, zero critical failures across the shadow period, guardrails confirmed working, and a rollback that has actually been tested. If any criterion fails, the launch is held, no exceptions.
Why criteria beat judgement
The reason to fix criteria ahead of time is that launch day creates pressure to ship, and pressure erodes judgement. A pre-agreed checklist makes the go-live decision objective: either the agent met the bar or it did not. This is the same discipline behind Gravity's internal quality gate, where reference agents must clear a fixed battery of checks before they are listed, rather than shipping on a builder's confidence. Tying the criteria to concrete numbers connects directly to AI agent evaluation metrics.
Launch in phases
When the criteria are met, resist the urge to flip the agent on for everyone at once. A phased rollout starts the agent on a small slice of real work, a fraction of traffic, one team, low-stakes cases first, and widens only as it proves itself. The first phase is where any problem your shadow testing missed will appear, and you want it to appear in front of a small audience, not your whole user base.
Widen on evidence, not schedule
Expand each phase based on what you observe, not a calendar. If the small slice runs clean and the metrics hold, widen; if anything looks off, pause and investigate before going further. A phased launch turns a risky all-or-nothing cutover into a series of small, reversible steps, each of which gives you a clean decision point. This is the same blast-radius thinking covered in how to limit agent actions, applied to the launch itself.
Have a rollback plan
The last piece of readiness is a way back. Before the agent goes live, know exactly how you will turn it off and undo its effects if something goes wrong, and confirm that path works by testing it. A rollback you have never exercised is a hope, not a plan, and the worst time to discover it does not work is during an incident.
A complete rollback covers two things: stopping the agent cleanly mid-run, and reversing actions it already took where that is possible. The clean-stop side is covered in how to stop an agent mid-task, and undoing completed actions in how to roll back an agent action. With staging passed, shadow mode clean, go criteria met, a phased plan ready, and a tested rollback in hand, going live becomes the calm last step of a careful process rather than a leap of faith.
Frequently asked questions
What is the difference between testing an agent and a go-live check?
Testing proves the agent does the right thing on known cases. A go-live check proves the agent is ready to touch real systems and real users safely. The first is about correctness; the second is about launch readiness: staging, dry runs, go criteria, a phased rollout, and a rollback plan.
What is shadow mode for an AI agent?
Shadow mode runs the agent on real, live inputs but blocks its actions, so it proposes what it would do without actually doing it. You compare its proposed actions against what should happen. It surfaces real-world failures that test data misses, with none of the risk of a live action.
What are go or no-go criteria for an agent launch?
Go or no-go criteria are the specific, measurable conditions the agent must meet before it goes live: an accuracy bar on a test set, no critical failures in shadow mode, working guardrails, and a tested rollback. If any criterion fails, the launch is held. They make the launch decision objective.
Should you launch an agent to everyone at once?
No. Use a phased rollout: start with a small slice of real traffic, watch closely, then widen as confidence grows. A phased launch limits the blast radius of any problem you missed and gives you a clean point to pause or roll back before most users are affected.
Do buyers need to run a launch readiness check?
On a platform like Gravity, the builder runs the agent through testing and launch readiness before it is listed, so you do not. Knowing what a good launch process looks like still helps you ask whether an agent was shadow-tested and how it rolls back if something goes wrong.
Three takeaways before you close this tab
- Ready is more than right. Correctness on test data does not prove safety against live systems.
- Shadow before you ship. Real inputs with blocked actions reveal the failures test data hides.
- Phase in, with a way out. Roll out gradually and keep a tested rollback for when something slips through.
Sources
- Google, "Site Reliability Engineering" (canarying and progressive rollouts), 2016, sre.google/sre-book/release-engineering/
- Anthropic, "Building Effective Agents", 2024, anthropic.com/engineering/building-effective-agents
- Gravity agent quality-gate notes, internal v1, 2026. Retrieved 2026-06-07.